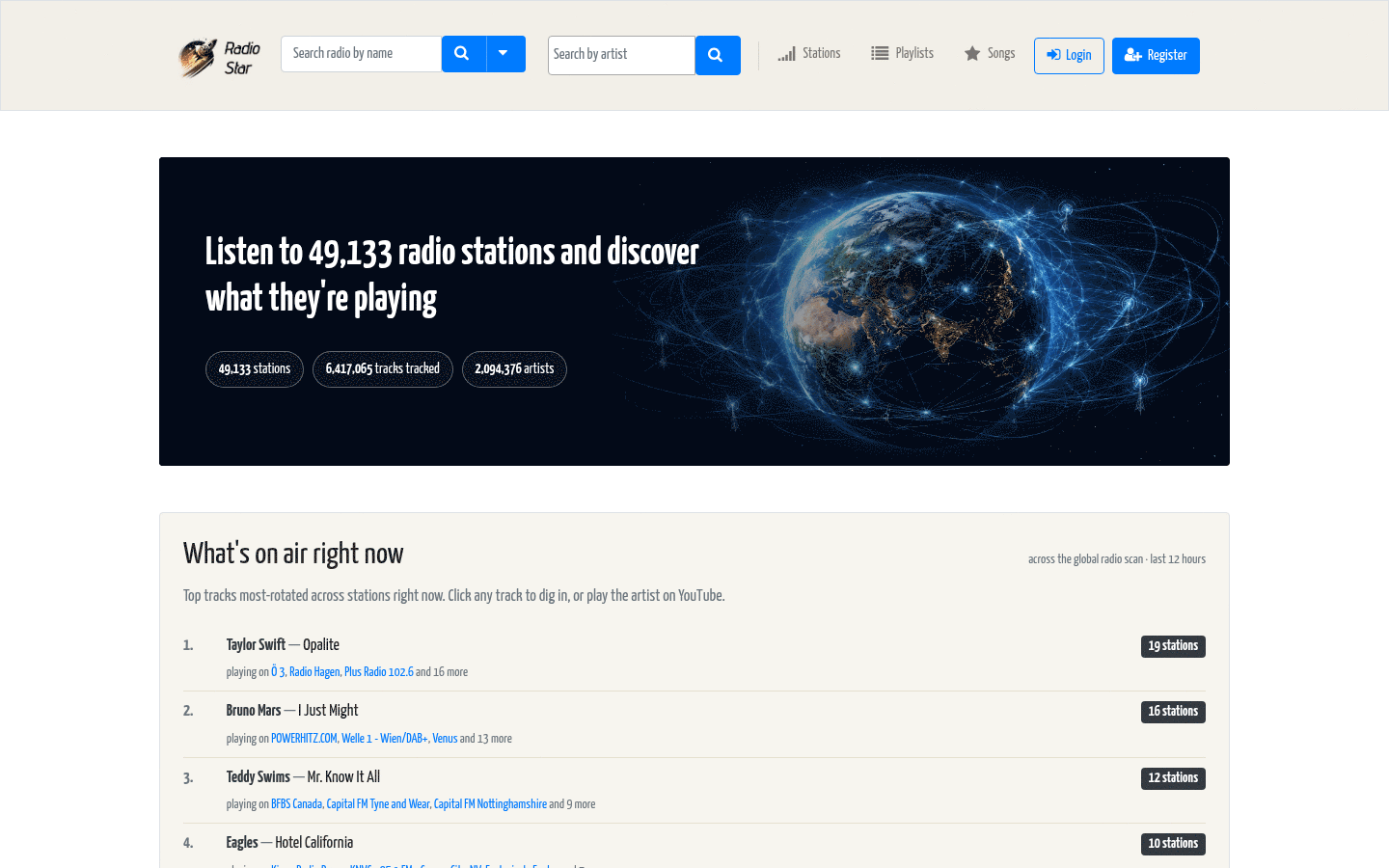
A music-discovery layer built on four years of structured rotation data — every track linked to the stations that play it, every artist indexed by where it gets rotated, every station playable as a YouTube mix of its own history.
The gap: why this layer is missing
The online-radio landscape has plateaued. TuneIn lists around 100,000 streams and lets you play them live. Radio Garden wraps a similar catalog in a globe-spinning interface — different UX, identical underlying data. radio-browser.info maintains an open station directory that dozens of apps consume via API. Last.fm tracks what people listen to through user scrobbles. MusicBrainz and Discogs hold static catalog metadata. Several of these are excellent at what they do.
None of them map what stations actually play.
TuneIn streams the live feed and discards everything after it passes through. Radio Garden does the same. Last.fm tracks listener behavior — what humans hear, not what stations broadcast. There is no service that captures the rotation of a radio station as a structured, queryable dataset over time. Ask a simple question — “which stations have rotated Foster The People in the last year, and what else do they play?” — and there is nowhere to get the answer.
This gap exists for a structural reason: the data only accumulates with time and infrastructure. To know what a station played in 2024, you needed to be polling it in 2024. To map artist rotation across thousands of stations, you need parallel sampling across thousands of streams running for years. It’s a time moat, not a clever algorithm — the kind of dataset that exists only if someone decided to start collecting it four years ago.
Radiostar.club is that collection. It has been sampling ICY stream metadata since May 2022, and as of mid-2026 it lists roughly 49,000 stations, with structured rotation data captured from around 35,000 of them. That history adds up to over 10.7 million track observations spanning more than 2 million artists — every track linked to where it was heard, every artist to the stations that rotate them, every station to its closest peers by playlist overlap. On the user side, this turns a flat radio listing into a music graph: listen to any station’s rotation as a YouTube mix, see where any artist gets played in the world, and discover new stations through what they share.
The product
Four surfaces carry the product. Each one answers “why come back here” rather than just “how do I press play.”
Station page — a station as a living object, not a stream URL
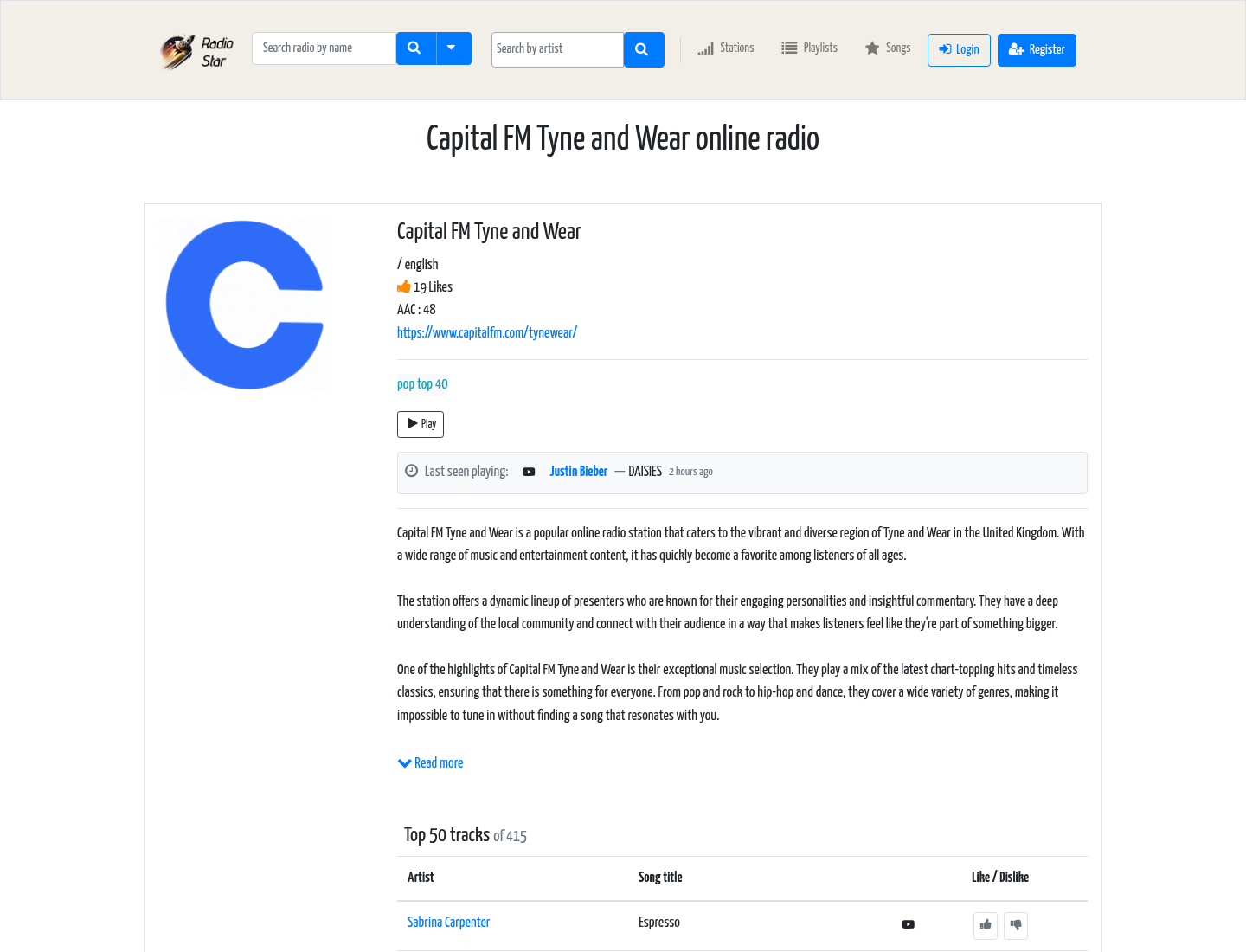
When a user lands on a station page, they don’t see a bare play button and a bitrate — they see what this station is actually playing right now and what it played before: a live “last seen playing” ping, a deduplicated tracklist ranked by how widely each track is rotated across the dial, and a row of similar stations built from item2vec embeddings (vector cosine + shared tracks). Any track can be played back on the spot via YouTube without leaving the page — the station turns from “a link to a stream” into an entry point into a listening session.
Artist page — where an artist actually gets rotated
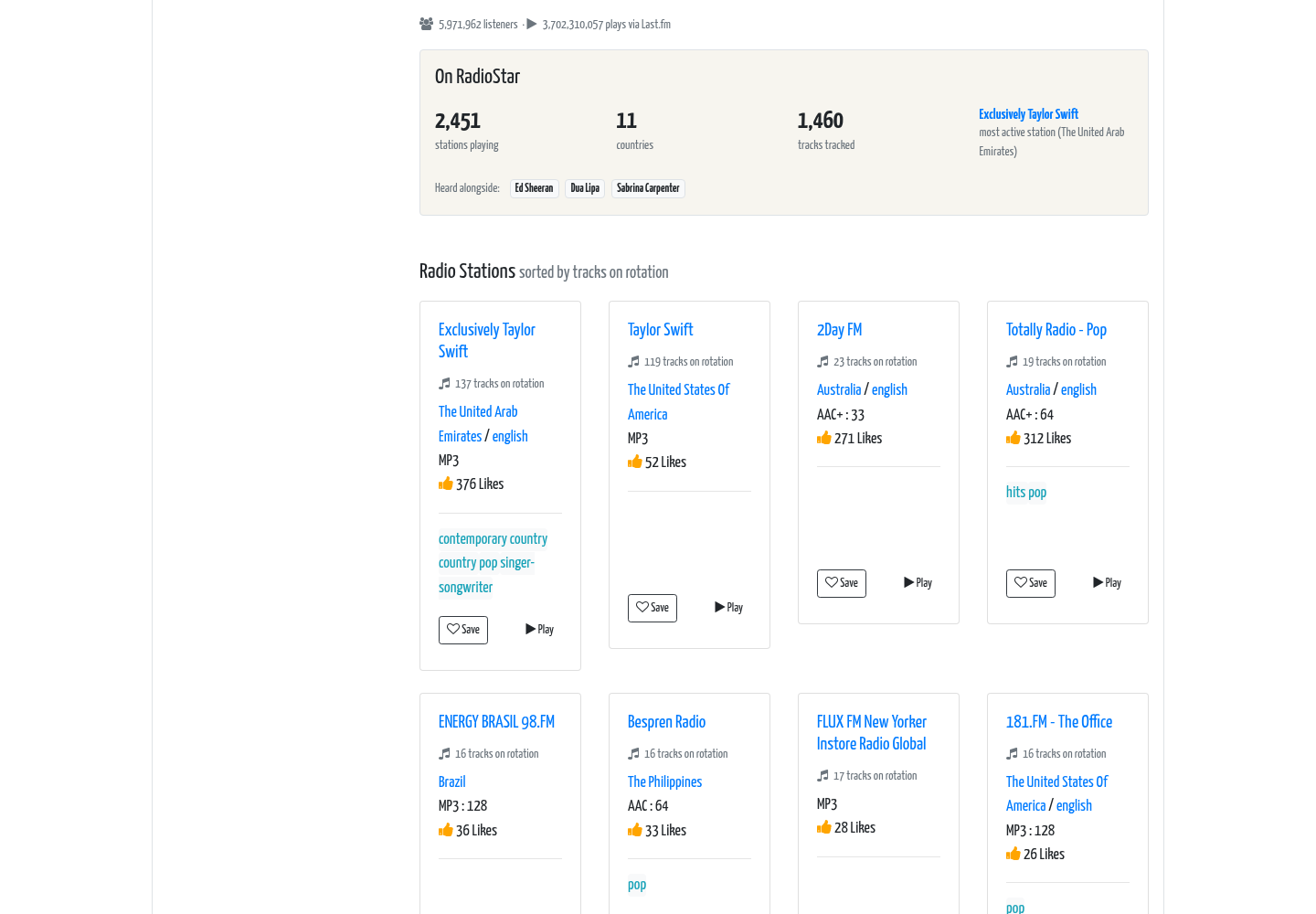
The artist page answers a question no streaming service does: which stations and which countries put this artist on air. Alongside bio and metadata (a MusicBrainz → Wikidata → Last.fm cascade), the user gets hard rotation stats — 2,451 stations playing, 11 countries, 1,460 tracks tracked, the single most-active station, and the artists this one is “heard alongside” — i.e. a map of the musical context an artist lives in around the world.
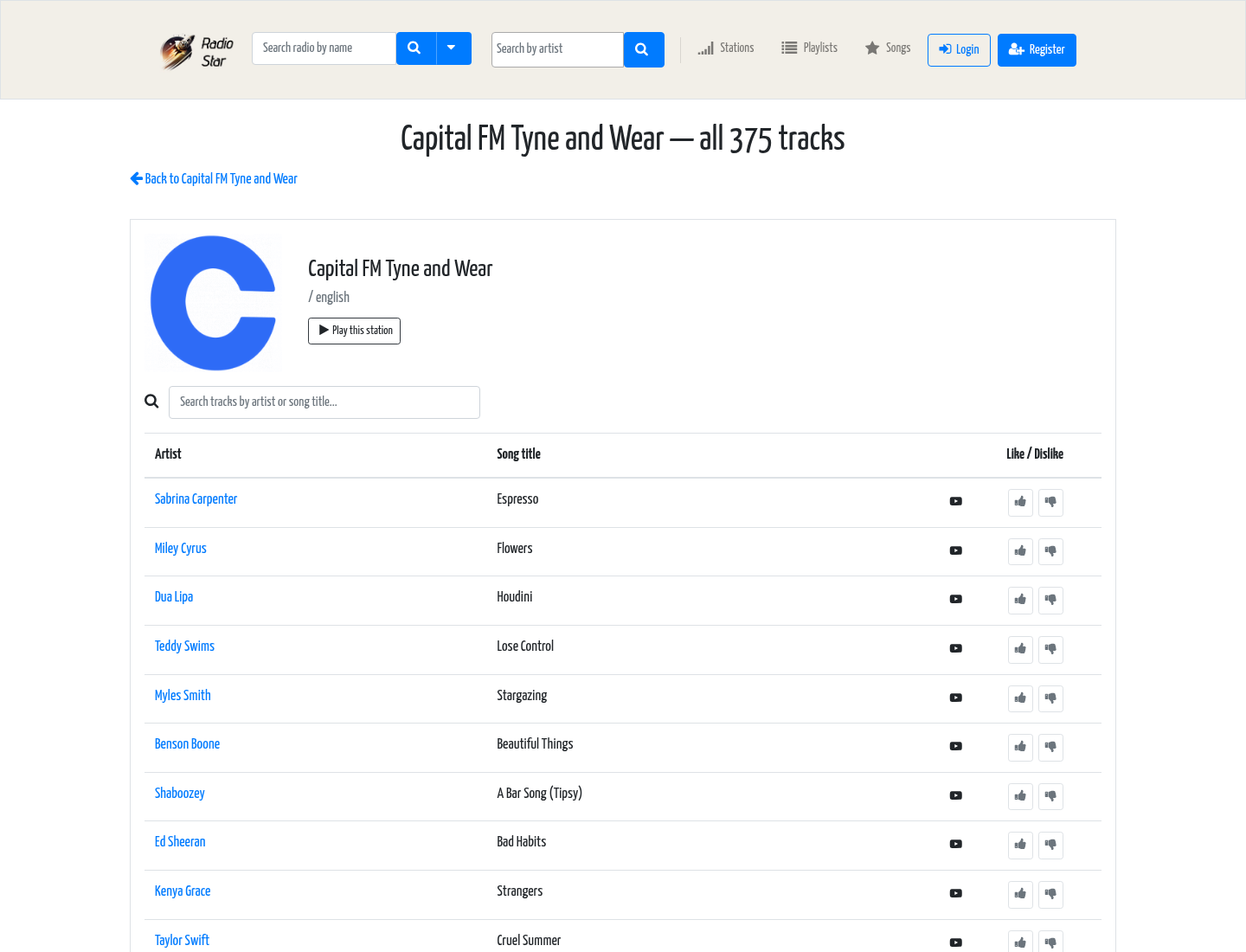
/tracks — a station’s full playlist, server-rendered, no pagination
For people who came specifically for the music, every station has its own /tracks page: the entire playlist it has ever been heard playing, in one server-rendered document — no “load more,” no infinite scroll (“Capital FM Tyne and Wear — all 375 tracks”). This is deliberate: the page is fully crawlable, loads as plain HTML, and works both as a discovery surface for Google and as a genuinely usable “full tracklist” with inline search and YouTube playback per row.
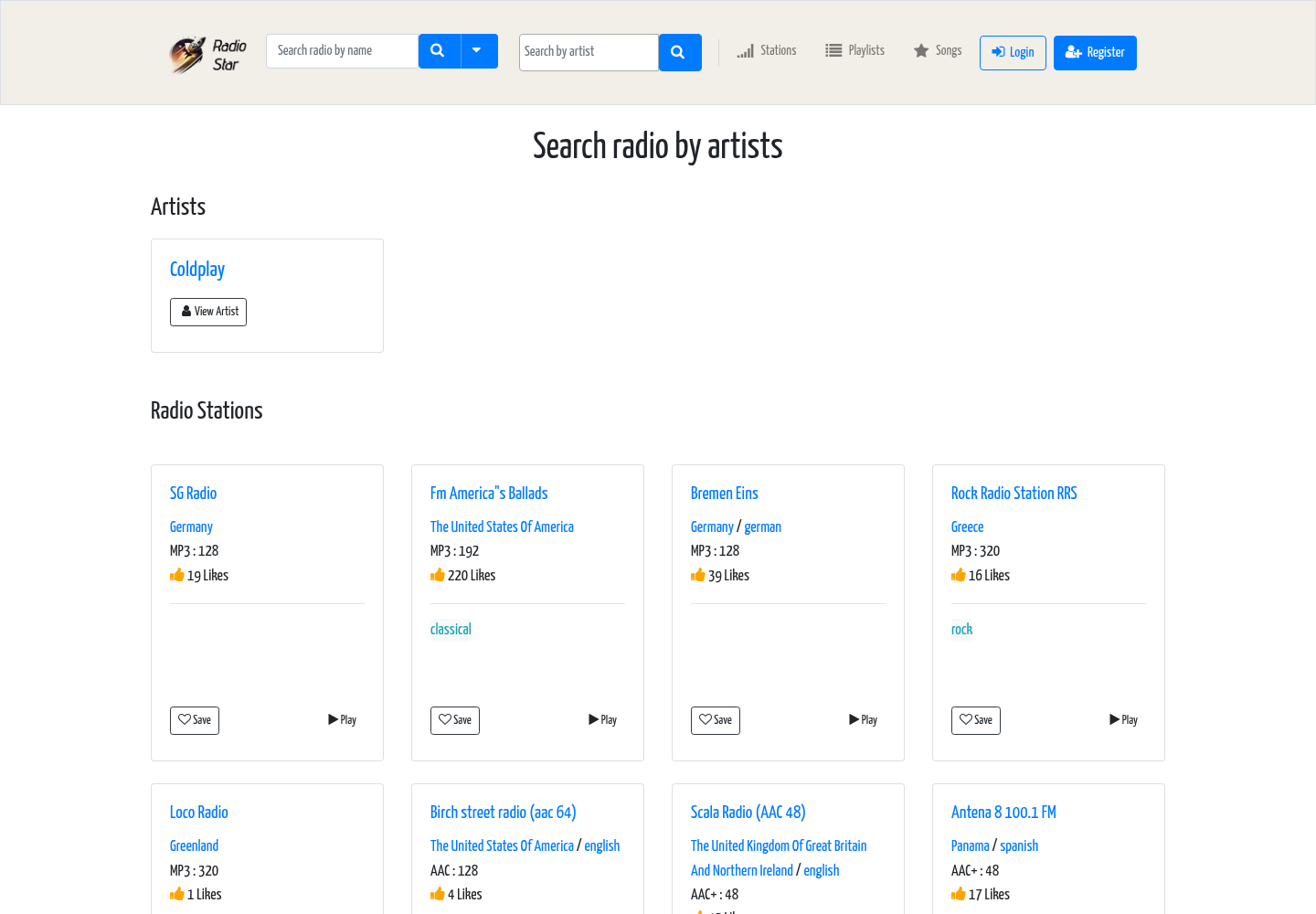
Search / discovery — find a station by what you want to hear
Discovery is built around music, not station names. You can search by country, genre, language, codec — or ask “find the stations that play this artist,” and the system returns the airwaves where that artist is actually in rotation, plus a link straight to the artist page. It answers the real user intent (“I want to hear X”) instead of making people guess a station’s name.
The technical foundation
Under the hood the product is split into two services that play to different strengths. A Laravel application running on FrankenPHP handles everything a visitor touches — the pages, authentication, Google sign-in, the station-owner dashboard and the admin panel — while a separate Flask API quietly does the heavy lifting behind it, answering every question that needs real computation: which stations are similar, where an artist gets rotated, what’s trending, what a station has played. The website never talks to the analytics layer directly; it asks the API, and the API decides how to answer.
That separation matters because the data has two very different shapes. The catalogue of stations, users and playlists is modest and relational, so it lives in MySQL. But the record of what has actually been heard on air is enormous — millions upon millions of track plays — and that lives in ClickHouse, a column store built for exactly this kind of question. Putting the play history there is what makes “this artist is on 2,451 stations across 11 countries” something the page can show instantly instead of a query that would crawl a normal database to a halt. Redis sits in front of all of it as the cache and as the queue that feeds new data in.
The data itself arrives through a small streaming pipeline. A scanner listens to station streams and reads the now-playing metadata they broadcast, drops each track onto a Redis queue, and a worker steadily folds those into ClickHouse. On top of that raw history, the system learns which stations resemble each other by training embeddings on listening patterns each week — the same idea behind “people who liked this also liked that,” applied to radio — and it fills out artist pages by stitching together public music databases.
The interesting engineering, though, was less about adding things than about keeping the site standing under relentless crawler traffic. Caching is deliberately careful: a failed upstream call is remembered briefly on purpose, so a single hiccup can never snowball into thousands of repeated requests — a lesson learned the hard way during a real incident. Pages that matter for discovery are rendered fully on the server so search engines see real content, not an empty shell waiting on JavaScript. And a good deal of work went into retiring an older database entirely and consolidating the play history onto ClickHouse, removing a whole moving part from the live path rather than leaving it to rot.
The SEO journey
Radiostar.club is four years old. By 2026 it should have moved out of Google’s sandbox into stable rankings on at least its niche keywords. It hadn’t.
The instinct is to blame Google’s bias against aggregators. After the Helpful Content Update of 2022–2024, the algorithm was tuned hard against the “list of scraped streams” pattern that defines this category. Reasonable theory. Wrong diagnosis.
The actual problem was simpler and uglier: the site had genuinely unique data, but none of it reached Google’s indexing surface. Every page was structurally indistinguishable from an aggregator clone. A station page titled “Le Son Parisien online radio” looked, to the crawler, like any other directory listing. The fact that the database held ~1,270 tracks played by that station, cross-referenced against ~35,000 other stations, with playlist-overlap relationships and per-artist rotation maps — none of it was visible above the surface. Same templated table fragment as a TuneIn clone, same generic title, no structured markup, no editorial framing. The unique data existed in the database, not on the page.
Five layers needed fixing in parallel.
Layer 1 — Surface metadata. Every station, artist and track page now gets a dynamically generated title built from structured data: track counts, top genres, country, rotation anchor artists. The same template produces ~49,000 distinct outputs. A real one, live today:
Before:
Music Art Club online radio
After:Music Art Club — Listen to 1,250 Tracks Played | Jazz Pop Radio from Greece
Meta descriptions follow the same pattern. The numbers in the title text alone shift the long-tail surface from a single branded query into dozens of permutations — “music art club playlist,” “music art club tracklist,” “jazz pop radio greece,” and so on.
Layer 2 — Editorial layer. A short, data-driven paragraph generated per station by an LLM fed structured JSON: rotation anchors from cross-station popularity, a year range from release aggregates, the top similar stations with overlap percentages. The prompt enforces factual constraints — no marketing language, no second person, no invented detail — and rotates through five system-prompt variants for structural diversity across the corpus. Hash-based regeneration means a paragraph only re-renders when the underlying data changes meaningfully. This is precisely the layer the Helpful Content Update was built to reward — “added value beyond raw data” — and the only way to ship it at tens-of-thousands-of-pages scale is structured-input LLM generation. Handwriting doesn’t scale; flat templates fail uniqueness checks.
Layer 3 — Page architecture. Pagination at ?page=2..39 was creating dozens of thin duplicates per station — same title, same template, a different 30-track fragment each. That’s replaced with a two-URL model: the station page renders the top 50 tracks plus the editorial layer; a dedicated /tracks page server-renders the full archive (1,000–3,000 tracks for an established station) at a single canonical URL with client-side search and sort. Old ?page=N URLs now 301-redirect to the tracks page. The result is one indexable URL per station-as-hub and one per full-rotation archive, with link equity consolidated into both instead of fragmented across ~39 thin pages.
Layer 4 — Schema.org. RadioStation and MusicPlaylist with track nodes as MusicRecording; MusicGroup on artist pages with sameAs links out to MusicBrainz and Last.fm; BroadcastService, ListenAction and BreadcrumbList to frame the entity. The full track array lives on /tracks for the heavy variant. This is the layer that lets Google read a page as a music entity rather than a wall of text — and surface it in music-rich SERP features.
Layer 5 — Performance. Every track row offers YouTube playback, which on a 1,000-plus-row page would mean either a Core Web Vitals disaster or a missing feature. The fix is a single shared sticky player, loaded lazily on first click, with track-row clicks routed through the IFrame postMessage API — one iframe per page, a facade on first paint, roughly 3 KB of overhead instead of ~500 KB per video.
Two notes on the current state. First, this work is incremental: rankings move over months as Google re-crawls, recalculates uniqueness, and redistributes link equity. The site is mid-rollout — most fixes deployed, the editorial layer backfilling across the corpus, rotation-observation timestamps only recently accumulating. Second, this is the kind of work that has to land before any off-page push makes sense. A Reddit launch or a press feature sends traffic to a sandboxed site that converts into thirty seconds of dwell time and a hard bounce, because nothing on the page tells the visitor — or Google — why it’s worth staying.
What this work resembles
The build pattern behind radiostar.club is the same one Zen Republic applies to client work: full-stack solo execution across data engineering, product and SEO, without expanding team headcount. Few agencies do all three layers in one engagement. The result is faster decision cycles, fewer handoffs, and a single point of accountability across product, engineering and SEO surface — which matters most when the diagnosis cuts across layers, as it usually does. The radio project is a public sandbox for that approach — every change documented, every architectural decision visible. Most client work isn’t public; this one is.
What’s in flight
Recently shipped
- Live “playing right now” homepage — top tracks aggregated across every station sampled in the last 12 hours.
- Artist cross-station signals — “2,451 stations playing · 11 countries · heard alongside …” now sit above the Last.fm biography on artist pages.
- Two-URL station architecture — hub page + canonical
/tracksarchive, with?page=Nlegacy URLs301-redirecting in.
In flight
- Editorial backfill across the corpus, rolling out in nightly LLM-pipeline batches with hash-based change detection.
- “Trending this week” — rotation-observation timestamps are now accumulating; the first usable weekly-window data follows once enough history banks behind the existing 12-hour now-playing block.
Next
- Filtered URL surfaces —
/genre/indie,/country/france,/radio/{slug}/decade/2010s(today these404), generating thousands of additional indexable hubs from data the database already holds.
This section is a living roadmap — revisited every couple of months as items move from “next” to “shipped.”